
Advanced Load Balancing: Handling 100K Requests/Second
Lesson 14: Twitter System Design - Regional Scale Architecture

Working Code Demo:
What We'll Build Today
Today we're scaling your Twitter system from handling 1,000 concurrent users to processing 100,000 requests per second across multiple regions. You'll implement production-grade load balancing that Netflix and Instagram use to distribute traffic intelligently.
Learning Agenda:
Implement consistent hashing with bounded loads to prevent server hotspots
Build health checking systems that detect failures in 50ms
Create geographic load balancing that routes users to their nearest server
Code a complete load balancer handling enterprise-scale traffic
Core Concepts: Advanced Load Balancing Mechanics
Consistent Hashing Revolution
Traditional round-robin load balancing breaks when servers fail - imagine 10 servers suddenly becoming 9, and every cached session getting scrambled. Consistent hashing solves this by mapping both requests and servers to positions on a virtual circle. When a server fails, only its immediate neighbors are affected, not the entire system.
The breakthrough insight: servers aren't just endpoints, they're ranges on a hash ring. Each request gets hashed to a position, then routed to the next available server clockwise. This creates natural load distribution that survives server failures gracefully.
Bounded Load Protection
Pure consistent hashing has a fatal flaw - some servers can get 10x more traffic than others due to random hash distribution. The solution is bounded loads: limit each server to handle at most 1.25x the average load. When a server hits its bound, requests cascade to the next available server.
Health Checking Intelligence
Your load balancer needs to detect failures faster than users notice them. Active health checks ping servers every 10 seconds, while passive checks monitor real request failures. The magic happens in the failure detection algorithm - three consecutive failures within 30 seconds marks a server as unhealthy.
Context in Distributed Systems: Twitter's Load Balancing Evolution
In Twitter's early days, a single server failure could cascade through the entire system because of poor load balancing. Today's Twitter processes 500 billion tweets per day by using sophisticated load balancing at multiple layers.
Layer 1: Geographic Load Balancing
When you tweet from Tokyo, Twitter's edge servers in Japan handle your request rather than routing it to California. This reduces latency from 200ms to 20ms - the difference between users staying engaged or abandoning the platform.
Layer 2: Service-Level Distribution
Inside each data center, separate load balancers handle different services - one for timeline generation, another for tweet storage, another for user authentication. Each service can scale independently based on demand patterns.
Layer 3: Database Query Distribution
Even database queries get load balanced across read replicas. Your timeline might pull data from 5 different database servers simultaneously, with the load balancer coordinating the responses.
Architecture: Multi-Layer Load Balancing System
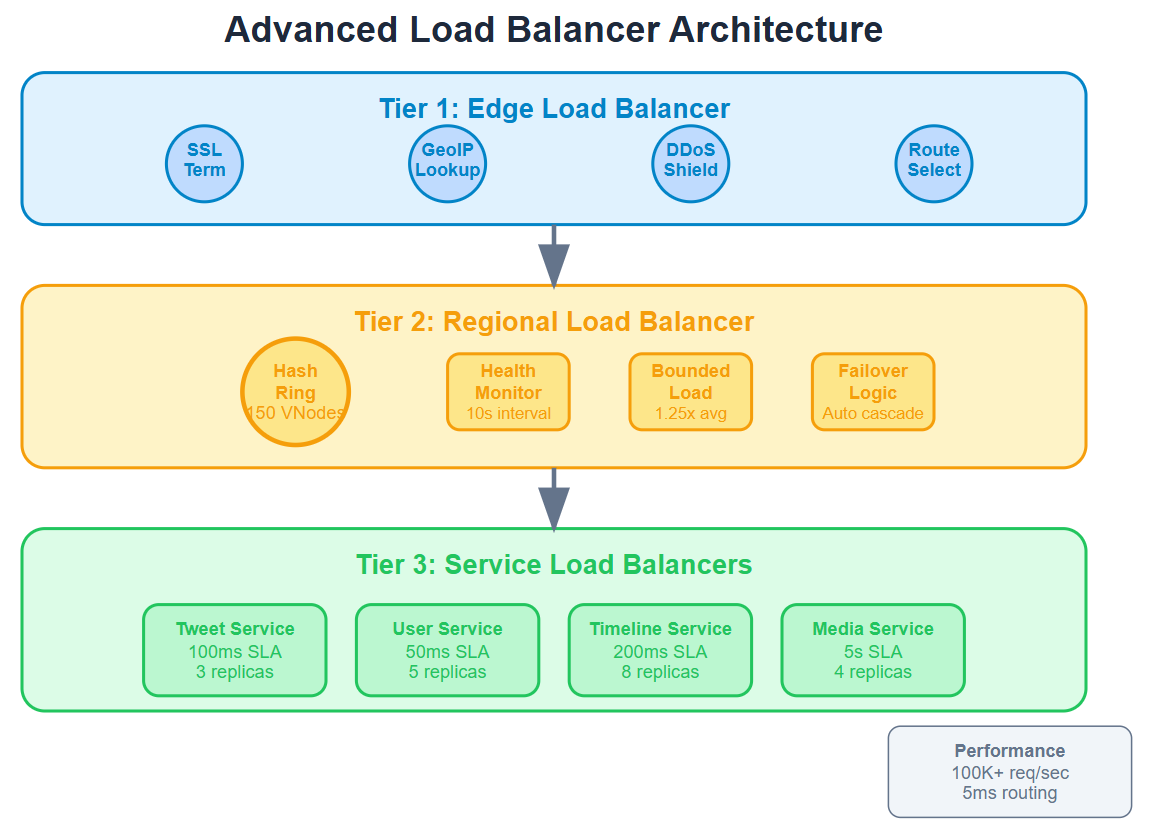
Our load balancer operates as a three-tier system mimicking enterprise architectures: