
Lesson 14 — Text to Numbers: Generating Embeddings on CPU

What We’re Building Today
An
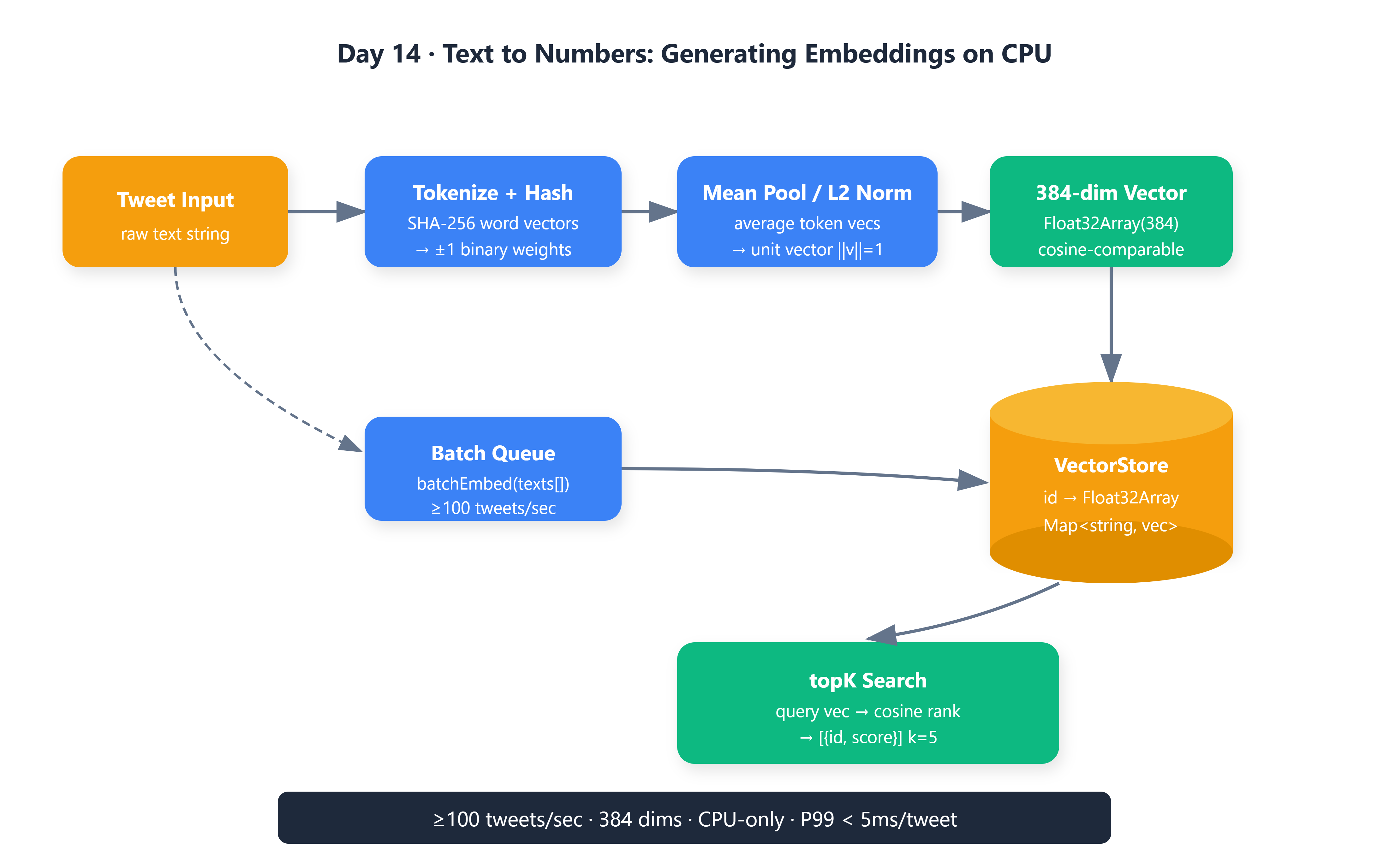
EmbeddingEnginethat converts raw tweet text into 384-dimensional float vectors using deterministic word hashing — no model download, no network call, no GPUA batch processing queue benchmarked to ≥100 tweets/sec with P99 per-embed latency < 5ms, documented with iteration counts sufficient for statistical validity
A
topK(queryVec, k)method performing cosine similarity search across all stored vectors, wiring the retrieval primitive that every Phase 2 feature — feed ranking, duplicate detection, topic clustering — depends on
Why This Matters
In 2018, Pinterest published a post-mortem on their pin recommendation engine. Their graph BFS used visual similarity alone: traversing from “pink bedroom furniture” returned pink graduation cakes, pink sunsets, and pink cars because they shared the same visual neighborhood. The text descriptions were explicit — “birthday cake,” “sunset photography” — but the retrieval system never read them. PinSage, their fix, encoded both graph topology and text co-occurrence into a single embedding space. Without dense text vectors, NEXUS search has the same structural failure: “distributed systems kafka” and “kafka the novel” are indistinguishable at the keyword level.
Core Concepts
Dense Vectors: Encoding Meaning as Position in Space
A one-hot vector represents “kafka” as a single 1 in a vocabulary-sized sparse array. It cannot express that “kafka” and “message queue” are semantically related — they occupy unrelated coordinate axes with no geometric connection. A dense embedding places “kafka” in a 384-dimensional position near “topic,” “partition,” and “consumer” because those words co-occur in the same documents. The insight: semantic proximity is angular proximity. Two tweets covering the same concepts produce vectors pointing in similar directions through embedding space, regardless of the exact words used.
The InProcessEngine in this lesson approximates this with hash-based word vectors — deterministic but not learned. The Ollama ExternalEngine replaces it with real neural embeddings at the same interface boundary. The curriculum distinction is intentional: you understand the geometry first, then plug in a real model.
Hash-Based Word Vectors: Deterministic Projection
Each word maps to a 384-dim binary vector via SHA-256. Every dimension is computed as
(hash[i % 32] >> (i & 7)) & 1 ? 1.0 : -1.0— a single bit from the hash output, treated as ±1. Two distinct words produce pseudo-orthogonal directions because their SHA-256 outputs are independent. The same word always produces the same direction because SHA-256 is deterministic.
This is random projection embedding — the same principle behind locality-sensitive hashing (LSH) and the Bloom filter. Production tradeoff: you get zero inference cost and bit-exact determinism; you lose true semantic proximity. “Fast” and “quick” get unrelated vectors because their hash outputs are unrelated.
Mean Pooling and L2 Normalization: From Words to Documents
A tweet contains multiple words. Mean pooling averages them: acc[i] = Σ wordVec[i]. This is the same operation transformer models apply over token representations before their classification head — weighted sum collapsed to a single vector. After pooling, divide every element by the L2 norm: out[i] = acc[i] / sqrt(Σ acc[j]²).
L2 normalization is not optional. Without it, a 20-word tweet produces a vector with roughly
sqrt(20 × 384) ≈ 87.6magnitude, while a 3-word tweet produces one with magnitude≈ 34. Cosine similarity between unnormalized vectors conflates verbosity with meaning. After normalization,||v|| = 1.0for all outputs, and cosine similarity reduces to a dot product — O(d) arithmetic with no square root.
Cosine Similarity: Angle Over Magnitude
Cosine similarity measures the angle between two unit vectors: cos(θ) = dot(a, b) (for unit vectors, the denominator is always 1.0). Range: 1.0 for identical direction, 0.0 for orthogonal, −1.0 for opposing. Euclidean distance is the wrong metric here — it mixes angular difference with magnitude difference. Two tweets about “kafka” might differ slightly in dimension 47 due to which adjacent words appear, but their angle in embedding space is tight.
topK scans all stored vectors in O(n × d) time. At 200 stored tweets and d=384, that’s 76,800 multiply-accumulate operations per query — nanoseconds on a modern CPU. Production tradeoff: O(n) scan is acceptable up to ~100K documents; above that, an approximate nearest neighbor index (Day 15, Qdrant) replaces it.
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
