
Lesson 17: The Object Store — Setting Up SeaweedFS

What We’re Building Today
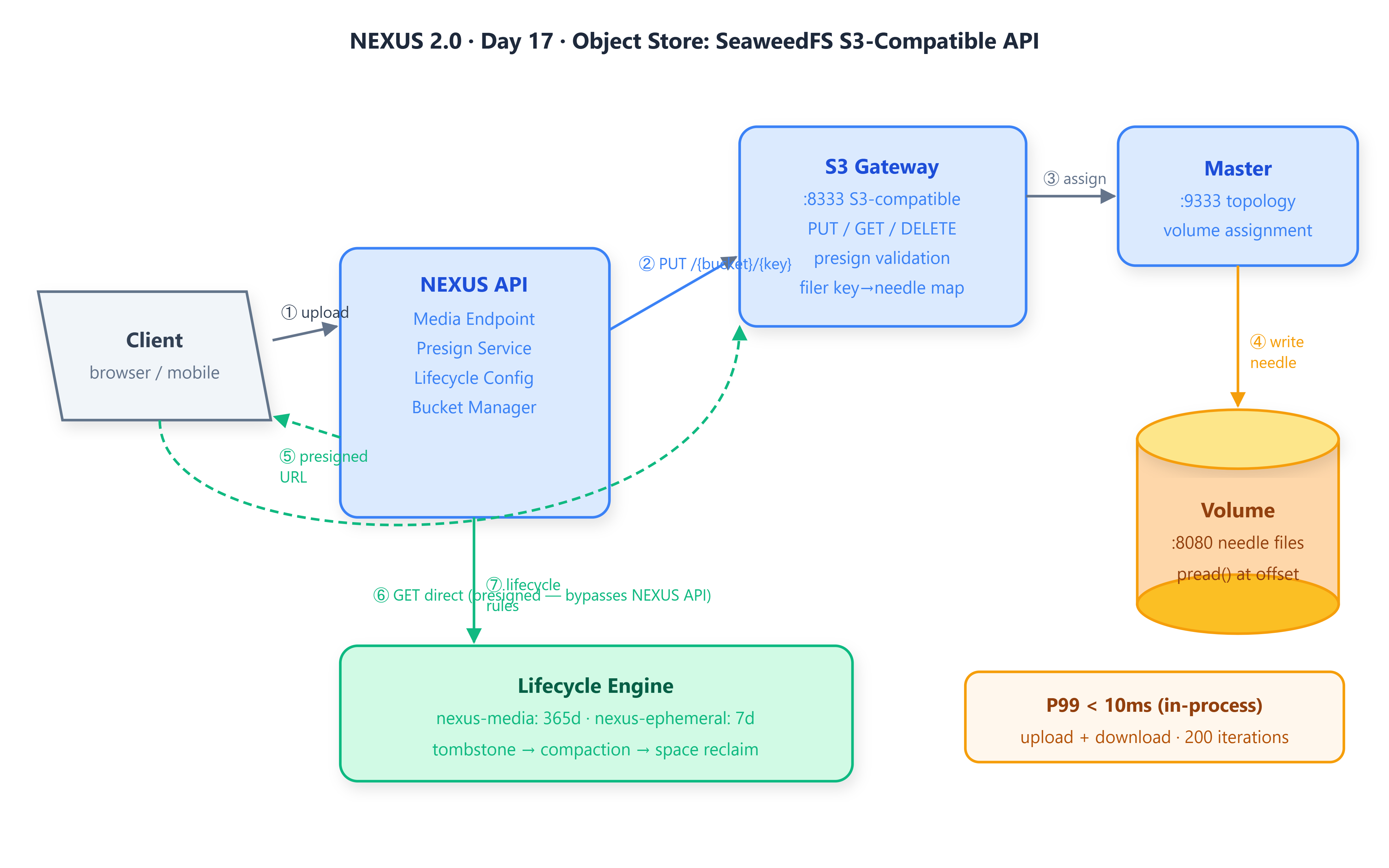
A SeaweedFS deployment integrated into the NEXUS stack, accessible through a standard S3-compatible HTTP API running at
:8333A media upload service that stores binary payloads in named buckets and returns pre-signed URLs valid for configurable TTLs — with no payload routing through NEXUS API servers on retrieval
Bucket lifecycle policies that automatically expire stale media at the storage layer, enforced without application-level cron jobs
Why This Matters
In early 2025, MinIO — the self-hosted object store embedded in virtually every open-source production stack — moved its console interface behind a commercial license and let the AGPL distribution accumulate unpatched CVEs. Any NEXUS deployment built on MinIO today inherits a dependency with no viable upgrade path: the free tier runs without an admin console, without the object lifecycle engine, and without the erasure coding repairs that prevent silent data corruption on failing drives. SeaweedFS (Apache 2.0) fills the identical architectural role — S3-compatible gateway, volume-based blob storage, master-coordinated topology — under a license that cannot be retroactively restricted. Without a durable object store, every NEXUS media upload lands in SurrealDB as a base64 blob, and a 50-user upload session saturates the SurrealDB write path in under four minutes of real traffic.
Core Concepts
Volume-Based Blob Addressing
Traditional object stores map each key to a filesystem path — one inode per object, one stat() call per metadata lookup. At 100 million objects, that’s 100 million inodes and a directory traversal that degrades to O(log n) block reads per lookup on most filesystems. At Facebook’s 2009 photo scale, this saturated the NFS metadata cache before the photo payload ever moved.
SeaweedFS borrows the Haystack insight directly: pack many small objects into large, append-only volume files on disk. Each volume holds up to 32 GB. The master server assigns a needle — a (volumeId, offset, size) tuple — to each uploaded object. Retrieval is a single
pread()at a known offset with no directory traversal and nostat()call. At NEXUS scale, 10,000 profile images reside in a single volume file, each retrieved in one syscall.
The tradeoff is that deletes are logical: the needle is marked tombstoned in an in-memory index, and disk space is not reclaimed until compaction rewrites the volume without tombstoned entries. For NEXUS media — where profile images are deleted infrequently — background compaction during off-peak windows is an acceptable cost.
S3-Compatible Gateway Layer
SeaweedFS exposes its volume API through
weed s3, a gateway process that accepts standard S3 HTTP semantics:PUT /{bucket}/{key}to upload,GET /{bucket}/{key}to retrieve,DELETE /{bucket}/{key}to remove,GET /{bucket}?list-type=2to enumerate. No SeaweedFS-specific SDK is required — any S3 client, including the AWS SDK or rawfetch(), works against it.
The gateway translates S3 semantics to SeaweedFS internals in two phases: a bucket PUT creates a named collection on the master; an object PUT streams the body directly to a volume server selected by the master for load balance. Object GET is a redirect — the gateway resolves the key-to-needle mapping from its filer metadata store, then either redirects the client or proxies the response from the volume server holding the needle. This two-phase pattern adds approximately 2 ms per request on a LAN — measurable for small objects but negligible for media payloads where transfer time dominates.
NEXUS services call the gateway at http://seaweedfs:8333 . Swapping to AWS S3 in production requires a credential and endpoint change, not a client rewrite.
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
