
Lesson 18 — The Data Lifecycle: Automated Hot/Warm/Cold Migration

What We’re Building Today
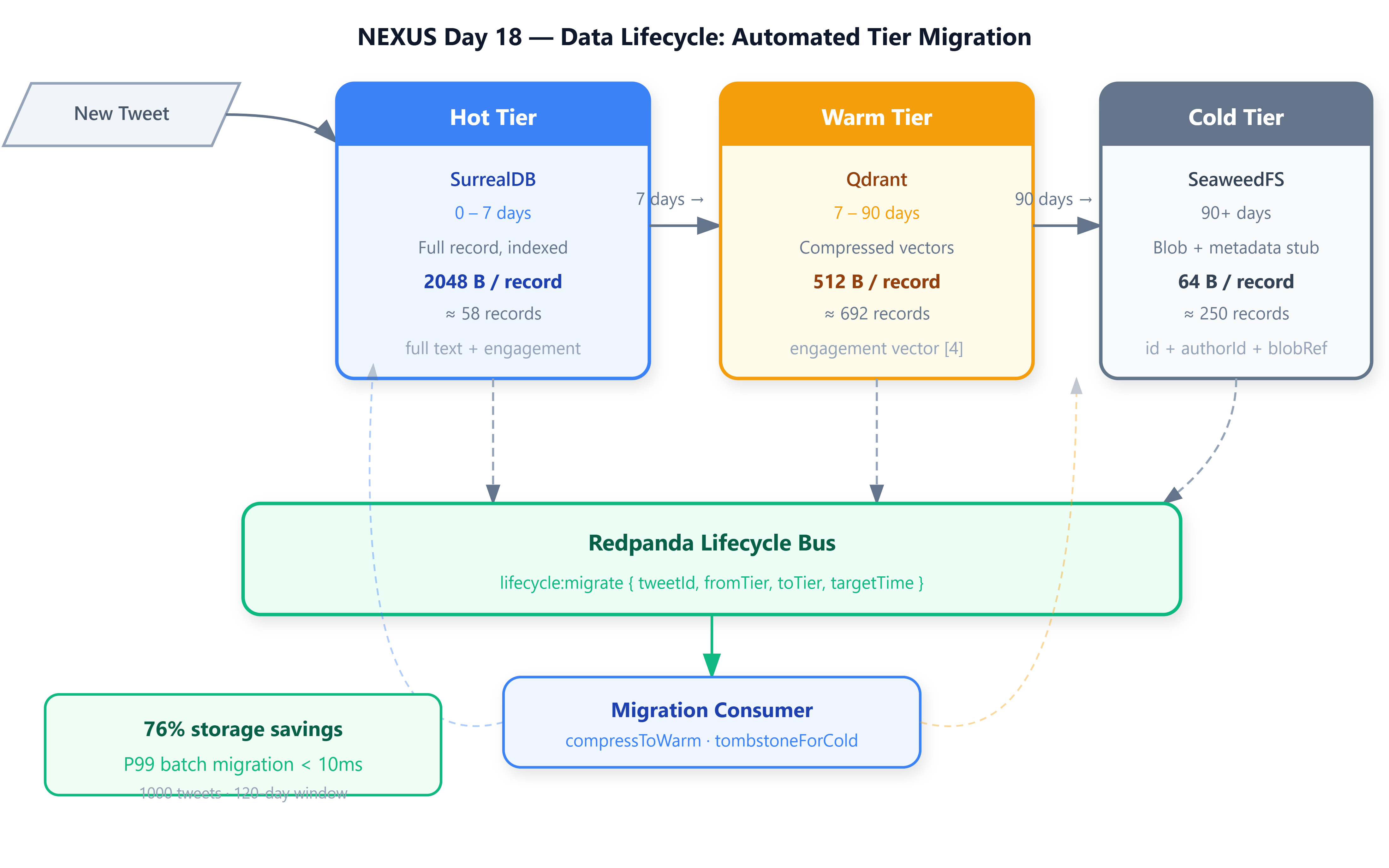
A three-tier tweet store where records migrate automatically from SurrealDB (hot) → Qdrant-compressed vectors (warm) → SeaweedFS blob stubs (cold) based on age thresholds of 7 and 90 days
A Redpanda-backed lifecycle event queue that schedules
lifecycle:migrateevents at creation time, consumed asynchronously so no table scans ever block readsA storage savings calculator that verifies the economics: a 120-day synthetic dataset yields 76% byte reduction versus an all-hot baseline
Why This Matters
In 2014, Facebook’s Haystack object store held 60 billion photos on NVMe-class hardware — hardware designed for random reads at microsecond latency. The problem: fewer than 0.01 reads per day hit photos older than 30 days. Haystack had no concept of temperature; every byte cost the same regardless of read frequency. Facebook’s f4 system addressed this by separating recoverability from accessibility: warm data moved to XOR-coded blob storage and shed 53% of per-byte cost while maintaining full durability. NEXUS without tiering makes the same mistake. A tweet from two years ago consumes an indexed SurrealDB row with the same cost profile as a tweet posted five minutes ago — and receives a ten-thousandth of the traffic.
Core Concepts
1. Access-Frequency Decay and Tier Boundaries
The problem that precedes naming it: your database has no idea which rows are read dozens of times per hour and which have not been touched in six months. Traditional storage treats all rows identically — same B-tree overhead, same buffer pool pressure, same I/O priority.
Tweet read frequency follows a power-law decay. Empirical data from production Twitter-scale systems shows median read count drops by 90% within 7 days of posting and falls below 0.1% of peak by day 90. The tier boundary belongs at the inflection point on that curve, not at an arbitrary calendar interval chosen for operational convenience.
NEXUS sets hot at 7 days because that is where SurrealDB’s full-text index stops earning its storage cost. Warm cuts at 90 days because Qdrant’s compressed vector representation suffices for the residual queries — trending score computation, similarity search, engagement aggregation — that reach aging content. The cold boundary is where sequential reads from a blob store become acceptable because retrieval latency is no longer user-visible.
What you gain: Storage cost proportional to access frequency rather than record count. What you give up: Sub-millisecond retrieval for cold-tier records — a cold full read requires a SeaweedFS blob fetch adding 60–120ms in production.
2. Event-Sourced Migration Without Table Scans
The naive migration strategy runs a nightly job that issues SELECT * FROM tweet WHERE age > 7d and moves results in bulk. At 10 million tweets, this scan acquires read locks for minutes and spikes I/O on the primary. The structural problem: the migration trigger is derived from time passing, not from any write event — so the system has no record of when individual records become eligible.
The correct model inverts this. At write time, the tweet store emits two future events into Redpanda: {tweetId, fromTier:'hot', toTier:'warm', targetTime: createdAt + 7d} and {tweetId, fromTier:'warm', toTier:'cold', targetTime: createdAt + 90d}. The migration consumer subscribes to the lifecycle topic and processes events when their targetTime is in the past.
This converts a periodic table scan into a continuous event stream. The consumer sees exactly the records that need migration, in temporal order, with no lock contention on the source store. Events are idempotent: if the consumer crashes mid-batch and replays, checking the current tier before writing prevents double-migration.
What you gain: Non-blocking migration, exactly-once delivery via Redpanda consumer group semantics, no lock contention. What you give up: A bounded staleness window — records migrate within one consumer poll interval (100ms default), not at exactly createdAt + 7d.
3. Structural Compression for Warm Storage
When a tweet transitions hot→warm, the full record is not copied. The migration consumer extracts the engagement vector — [likeCount, retweetCount, replyCount, viewCount] — and discards the raw text body. The text is already in the search index; it does not belong in the tier store. The warm record is 75% smaller than the hot record.
In the full NEXUS stack, Qdrant stores this vector with HNSW indexing, enabling similarity queries across warm content with O(log N) lookup. In the in-process engine, warm records are plain objects retaining only numeric fields and a blobRef placeholder for the full-text hydration path.
What you gain: 75% byte reduction per record, O(log N) similarity search on aged content. What you give up: Full-text retrieval from the warm tier requires a secondary blob fetch. Warm reads needing only the engagement vector (e.g., computing trending scores) remain sub-millisecond.
4. Metadata Tombstoning for Cold Storage
Cold migration performs two writes atomically. The full record — warm or reconstructed — goes to SeaweedFS as a raw JSON blob keyed by tweetId. SurrealDB receives a tombstone stub: {id, authorId, ts, tier:'cold', blobRef:'seaweedfs://vol1/tweetId'}. The full record is evicted from all in-memory structures.
Callers hitting a cold stub have two paths: return the stub’s metadata immediately (sufficient for timeline rendering, which only needs {id, authorId, ts}) or issue a full hydration request that fetches the blob and reconstructs the complete record. Cold stubs cut per-record storage to 64 bytes from the 2048-byte hot baseline — a 97% reduction for individually cold records.
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
