Lesson 15: Database Sharding Design
Breaking the Single Database Bottleneck

Video:
What We're Building Today
Today we're solving the database bottleneck that will crush your Twitter clone when it grows beyond a few thousand users. We'll implement intelligent database sharding that automatically distributes user data across multiple databases, handles hot shards (those celebrity users with millions of followers), and seamlessly rebalances when adding new database nodes.
Main Learning Points:
Design sharding keys that prevent data hotspots
Implement user-based and geographic sharding strategies
Build automatic shard rebalancing for operational resilience
Create cross-shard query coordination for complex operations
The Database Wall Every Growing System Hits
Remember last week when we built a load balancer handling 100K requests/second? That's impressive, but here's the reality check: all those perfectly balanced requests are still hitting the same database. It's like having six lanes of traffic merging into a single-lane bridge.
Instagram learned this the hard way in 2012 when their single PostgreSQL database became their biggest constraint, even with read replicas. They had to completely re-architect their data layer using sharding strategies similar to what we're building today.
Core Concepts: Why Sharding Transforms System Architecture
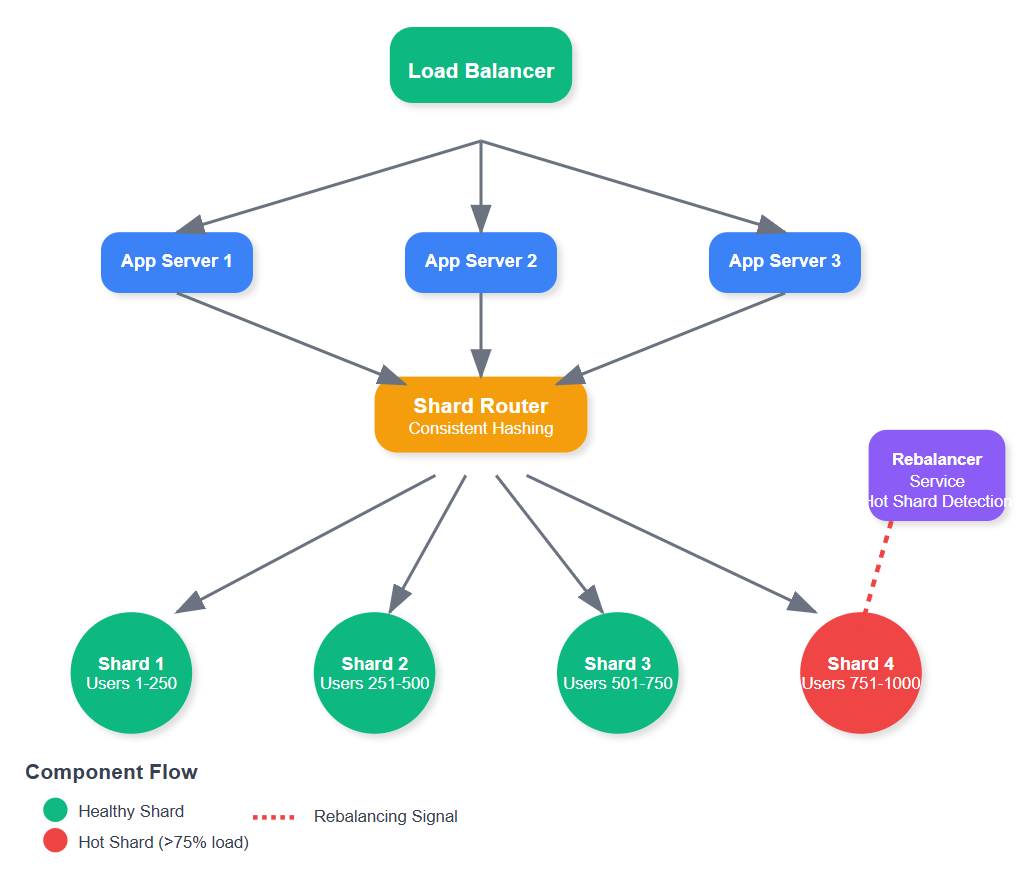
Database sharding splits your data across multiple independent databases, each handling a subset of users or content. Unlike read replicas that just copy data, shards contain different data entirely.
The magic happens in the shard key selection - the algorithm that determines which database stores which user's data. Choose poorly, and you'll have one database handling all the celebrities while others sit idle. Choose wisely, and your system scales linearly.
Workflow Overview:
Incoming request contains user ID or tweet data
Shard router calculates which database shard handles this data
Request gets routed to specific database instance
Response returns through the same shard-aware path
Context in Twitter's Distributed Architecture
In our Twitter system, sharding sits between your load balancer (from last week) and the timeline generation service (next week's lesson). The load balancer distributes requests across application servers, but each application server needs intelligent database routing.
This creates a three-tier scaling strategy:
Tier 1: Load balancers distribute requests across app servers
Tier 2: Shard routers distribute data access across databases
Tier 3: Database shards handle subset of total data
Real Twitter uses a hybrid approach with user-based sharding for tweets and timeline data, plus geographic sharding for global distribution. Our implementation mirrors this production pattern.
Architecture Deep Dive
Component Architecture