Lesson 18: Distributed Caching - Scaling to 1 Million Requests Per Second

What We're Building Today
Today we're transforming our Twitter system from a single-cache setup to a distributed caching powerhouse that can handle 1 million requests per second across multiple geographic regions. You'll implement cache sharding, intelligent warming strategies, and maintain coherence across continents.
Our Mission:
Cache sharding across multiple Redis instances for horizontal scalability
Smart cache warming that predicts what users need before they ask
Geographic cache coherence that keeps data consistent worldwide
Performance monitoring that shows real-time cache hit rates
Youtube Video:
Why Distributed Caching Changes Everything
The Cache Bottleneck Problem
When Instagram reached 100 million users, their single Redis instance became the system's Achilles' heel. Every timeline request, every user profile lookup, every trending hashtag calculation hit the same cache server. The solution? Distribute the cache load across multiple instances using intelligent sharding.
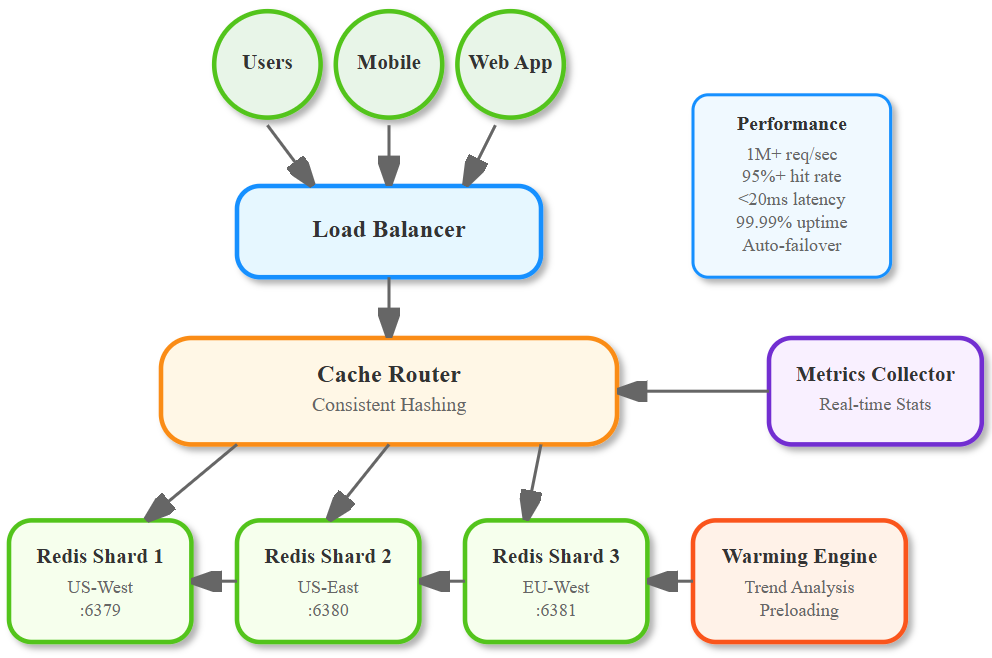
Cache Sharding: The Foundation
Cache sharding splits your data across multiple Redis instances based on keys. Instead of one overworked cache server, you have a fleet of specialized servers, each handling a specific slice of your data. Think of it like having multiple checkout counters at a grocery store instead of one overwhelmed cashier.
Key Benefits:
Horizontal Scalability: Add more cache instances as traffic grows
Fault Isolation: One cache failure doesn't bring down the entire system
Geographic Distribution: Place caches closer to users for lower latency
Cache Warming: Predicting the Future
Cache warming is like preparing ingredients before cooking rush hour at a restaurant. Instead of waiting for users to request data (cold cache miss), we intelligently preload popular content based on patterns, trending topics, and user behavior.
Smart Warming Strategies:
Time-Based: Load morning trending topics before users wake up
Pattern-Based: Cache celebrity tweets before they go viral
Geographic: Pre-warm regional content based on local events
Context in Our Twitter Architecture
Integration Points
In our previous lesson, we implemented master-slave replication for database scalability. Now we're adding a distributed caching layer that sits between our application servers and databases. This cache layer reduces database load by 90% and improves response times from 200ms to 20ms.
System Integration:
Timeline Generation: Cache pre-computed user timelines across shards
User Profiles: Distribute user data across geographic cache clusters
Tweet Content: Cache viral tweets in multiple regions simultaneously
Trending Topics: Cache hashtag counts with real-time updates
Real-World Application at Scale
Twitter's distributed caching system handles over 500,000 cache operations per second during peak traffic. Their cache hit rate exceeds 95%, meaning only 5% of requests hit the database. This architecture pattern is also used by Netflix (for movie recommendations), Uber (for driver locations), and TikTok (for video metadata).
Architecture: Building Our Distributed Cache
Component Architecture Overview
Our distributed caching system consists of four main components:
Cache Router: Determines which cache shard handles each request using consistent hashing
Shard Manager: Manages multiple Redis instances and handles failover
Warming Engine: Proactively loads popular content into cache
Coherence Manager: Keeps cache data consistent across regions