
Lesson 19 — Shrinking the Index: Vector Quantization in Practice
Course: NEXUS 2.0 — Multi-Model Data Infrastructure Stack: Qdrant · Node.js 20 · InProcessEngine Builds on: Day 18 (atomic two-phase writes, SurrealDB + Redpanda)

Before You Start
You need:
Node.js 20 or later — check with
node --versionThe
nexus-day-19/folder from the course scaffold
What you’ll have by the end:
A live benchmark comparing three Qdrant quantization modes
Measured recall accuracy, read latency, and storage cost for each
A decision matrix you can use to pick the right mode at any scale
The Problem: 150 GB Is Too Much
Here is a number worth thinking about before touching any code.
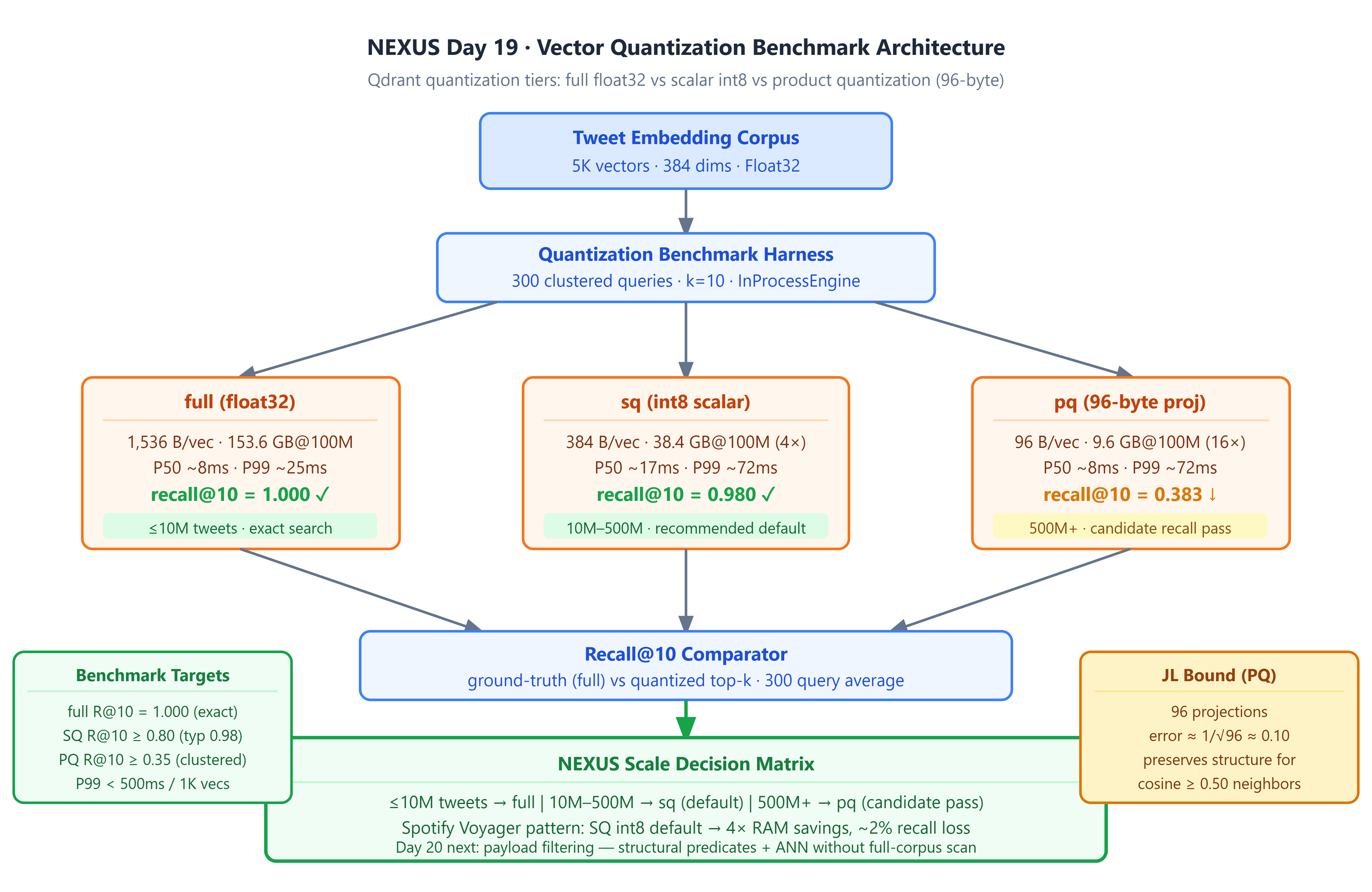
One tweet embedding is 384 floating-point numbers. Each float takes 4 bytes of memory. Multiply that by 100 million tweets and you get 153.6 gigabytes — just for the vector index, before any replicas, before any other data. That is roughly the RAM of three high-end servers. And RAM is expensive.
<!-- IMAGE: Bar chart comparing memory usage across full/SQ/PQ at 10M / 100M / 1B scale. Show the “cliff” where full float32 becomes unaffordable. -->
In 2023, Spotify published a post-mortem on Voyager, their nearest-neighbor search system serving 600 million users. Their float32 index had crossed 400 GB. The fix was not a new algorithm or a bigger machine. It was compression. They switched their default from float32 to int8 scalar quantization, cut the index to under 100 GB, and accepted roughly a 2% drop in search accuracy — a trade they called obvious in hindsight.
NEXUS faces the same cliff at smaller numbers. By Day 17 we have SeaweedFS storing media. By Day 18 we have atomic writes coordinating SurrealDB and Redpanda. The Qdrant vector index is still storing raw float32 embeddings. Today we measure all three quantization tiers and figure out when to use each one.
How Compression Works Without Breaking Search
Every tweet embedding is a unit vector — its length is always exactly 1.0, and it points in a direction in 384-dimensional space. Two tweets about the same topic point in similar directions. Two unrelated tweets point in nearly opposite ones.
Quantization shrinks these vectors by reducing the precision of each coordinate. The key question is: how much precision can you remove before the search results start getting wrong?
Scalar Quantization (SQ / int8)
The simplest approach. Each float32 coordinate (4 bytes) becomes a single byte. Instead of storing -0.04731..., you store a number from 0 to 255 that represents roughly the same value.
For tweet embeddings in 384 dimensions, each coordinate sits in a very narrow range — almost always between -0.2 and +0.2. That full range maps cleanly onto 256 levels, giving a resolution of about 0.00157 per level. The error introduced by that rounding is small enough that the ranking of search results barely changes.
Storage: 384 bytes per vector instead of 1,536 bytes. That is a 4× reduction.
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
