Lesson 27: Advanced Stream Processing with Kafka Streams

What We’re Building Today
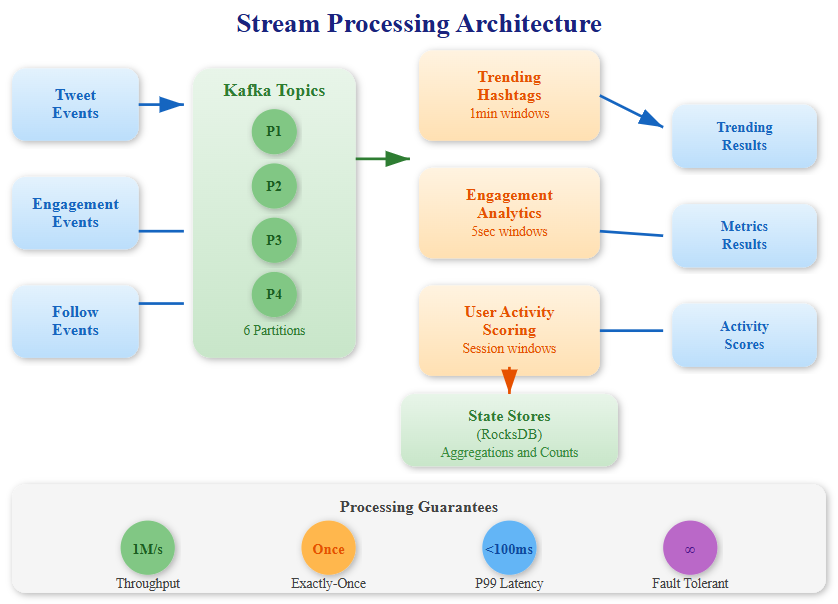
You’ve just finished handling celebrity users with millions of followers. Now imagine this: every time someone posts a tweet, likes something, or follows someone, you need to instantly update trending topics, personalized recommendations, and real-time analytics dashboards. We’re talking about processing 1 million events per second while guaranteeing that each event is processed exactly once—no duplicates, no lost data.
Today, we’ll build a production-grade stream processing system using Apache Kafka Streams that handles:
Real-time tweet engagement analytics (likes, retweets, replies per second)
Trending hashtag detection within 5-second windows
User activity scoring for recommendation engines
Exactly-once processing guarantees even during failures
Target: Process 1M events/second with sub-100ms latency and zero data loss.
Why Stream Processing Changes Everything
Traditional batch processing reads data, processes it, then writes results—think analyzing yesterday’s tweets to find trends. Stream processing does this continuously as data arrives. When a celebrity with 50M followers posts a tweet (from our last lesson), we don’t wait to batch process the reactions; we need real-time updates.
Netflix uses stream processing to update “Top 10” lists as you watch. Uber processes driver locations every second to match riders. Twitter’s trending topics update constantly based on streaming tweet data. Without stream processing, social media would feel like reading yesterday’s newspaper instead of having live conversations.
The magic happens when you combine stateful processing (remembering counts, aggregations) with fault tolerance (surviving server crashes) and exactly-once semantics (no duplicates or losses). This is computationally hard but essential at scale.