Lesson 29: Search Infrastructure Scaling
Building Ultra-Fast Search for Billions of Tweets

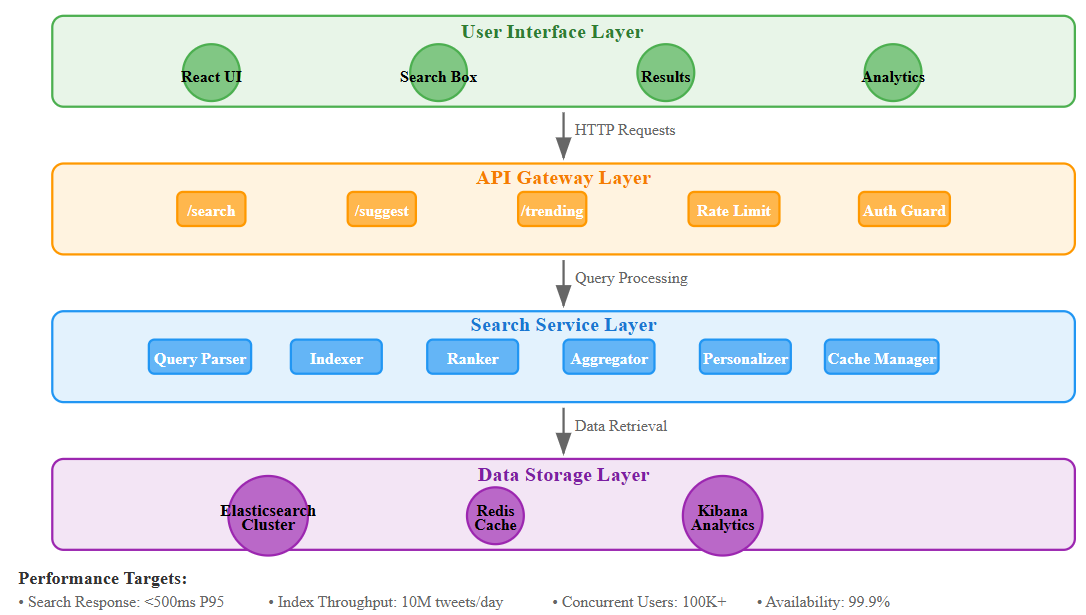
What We’re Building Today
Today we’re tackling one of Twitter’s most challenging problems: how do you search through billions of tweets in under a second? We’ll build a production-ready search infrastructure that can handle 10 million tweets per day while delivering results faster than you can blink.
Our agenda:
Design distributed Elasticsearch cluster architecture
Implement real-time tweet indexing pipeline
Build relevance scoring with personalization
Create search API with sub-second response times
Core Concepts: Distributed Search at Scale
The Search Challenge
Imagine trying to find a specific conversation in a library with 500 billion books, and new books are being added every second. Traditional databases crumble under this workload - we need specialized search engines.
Elasticsearch as Our Foundation
Elasticsearch isn’t just a search engine; it’s a distributed document store built for real-time search. It automatically partitions data across multiple nodes (sharding) and creates inverted indexes that make text search lightning fast.
Real-Time Indexing Pipeline
Every tweet must be searchable within seconds of posting. We’ll build a pipeline that processes tweets as they’re created, extracts searchable content, and updates our search indexes without blocking user queries.
Relevance Scoring
Not all search results are equal. We combine multiple signals: recency (newer tweets rank higher), popularity (viral content gets boosted), and personalization (tweets from people you follow matter more).
Context in Distributed Systems
Integration with Twitter Architecture
Our search infrastructure sits between the content creation system (from Lesson 28’s moderation) and the user-facing API. When users post tweets, they flow through moderation, then immediately into our search pipeline.